Linear systems can be big¶
- We take a continious problem, discretize it on a mesh with $N$ elements and get a linear system with $N\times N$ matrix.
- Example of a mesh around A319 aircraft
(taken from GMSH website).
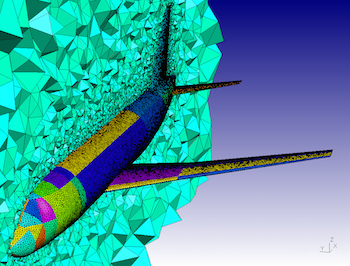
The main difficulty is that these systems are big: millions or billions of unknowns!


